코딩 에이전트 서비스의 확장 어려움: 대규모 GLM-5 디버깅에서 얻은 교훈
hackernews
|
|
📰 뉴스
#하드웨어/반도체
원문 출처: hackernews · Genesis Park에서 요약 및 분석
요약
GLM-5 시리즈가 복잡한 코딩 에이전트 작업에서 매일 수억 건의 요청을 처리하면서 고부하 상황에서 오류가 발생했습니다. 연구팀은 몇 주간의 조사와 스트레스 테스트를 통해 저수준 경합 조건 버그를 식별하고 수정했습니다. 이를 통해 시스템 병목 구간을 최적화하여 추론 시스템의 안정성과 효율성을 크게 개선했습니다.
본문
 2026-04-30 · Research Scaling Pain of Coding Agent Serving: Lessons from Debugging GLM-5 at Scale Our belief in Scaling Laws has not only driven continuous breakthroughs in model parameters and data scale, but has also pushed infrastructure engineering toward its limits. This process inevitably comes with growing pains, which we refer to as **Scaling Pain**. As large language model applications move beyond simple dialogue and toward more complex, long-horizon Coding Agent tasks, our inference infrastructure has come under unprecedented pressure, serving hundreds of millions of Coding Agent requests every day. Over the past few weeks, some users encountered several types of abnormal outputs when using the GLM-5 series for complex Coding Agent tasks, including garbled output, repetition, and rare-character generation. These issues do not appear under standard inference settings. They only emerge in high-concurrency, long-context Coding Agent workloads, making them extremely difficult to reproduce reliably. After several weeks of investigating, debugging, and stress testing, the team eventually identified and fixed several independent low-level race-condition bugs. We also implemented targeted optimizations for the underlying system bottlenecks revealed during this process, significantly improving both the stability and efficiency of the inference system. In this post, we share the lessons learned from this investigation, with the hope of helping the community better understand and overcome the Scaling Pain of Coding Agent inference. # 1. From Offline Reproduction to Anomaly Detection Since March, we have observed three types of abnormal phenomena in GLM-5 through online monitoring and user feedback: **garbled output** , **repetition** , and **rare-character generation**. At first glance, these phenomena resemble the “quality degradation” often seen in long-context scenarios. However, since no reduced-precision or accuracy-compromising optimization had been deployed, the more important question was whether these anomalies originated from the model itself or from the inference infrastructure. If the issue were caused by the model, the abnormal behavior would likely be stable and reproducible for specific inputs. By contrast, if the issue were correlated with system pressure or runtime state, it would more likely point to bugs in the inference infrastructure, such as request scheduling, state management, or cache consistency. At the beginning of the investigation, we replayed user-reported bad cases locally and repeatedly ran the same requests hundreds of times. However, we were unable to reproduce the anomalies, suggesting that the model itself was unlikely to be the root cause. To better approximate the online environment, we anonymized production logs while preserving the original concurrency distribution and request timing as much as possible, and then performed full-scale local replay. Initially, the anomalies still did not appear. They became reproducible only after we adjusted the prefill-decode disaggregation ratio and continued increasing system load to simulate peak-time Prefill backlog and KV Cache pressure on the Decode side. Under these conditions, we were able to reproduce approximately 3–5 abnormal outputs per 10,000 requests. The fact that these failures were independent of request content but correlated with system pressure suggested that the root cause likely lay in inference-state management under high load. Meanwhile, the offline reproduction rate was still lower than the rate observed by users, indicating that our detection method might still miss some cases or that certain triggering conditions had not yet been fully covered. Automatically detecting anomalous outputs was itself a challenge. Among the three anomaly types, repetition was relatively easy to identify, whereas garbled outputs and rare-character generation were much harder. We tried heuristic methods such as regular expressions and character-set matching, as well as model-based classifiers. The former suffered from both false negatives and false positives, while the latter was too consuming for large-scale ablation experiments. As a result, anomaly detection became a bottleneck in the debugging process. 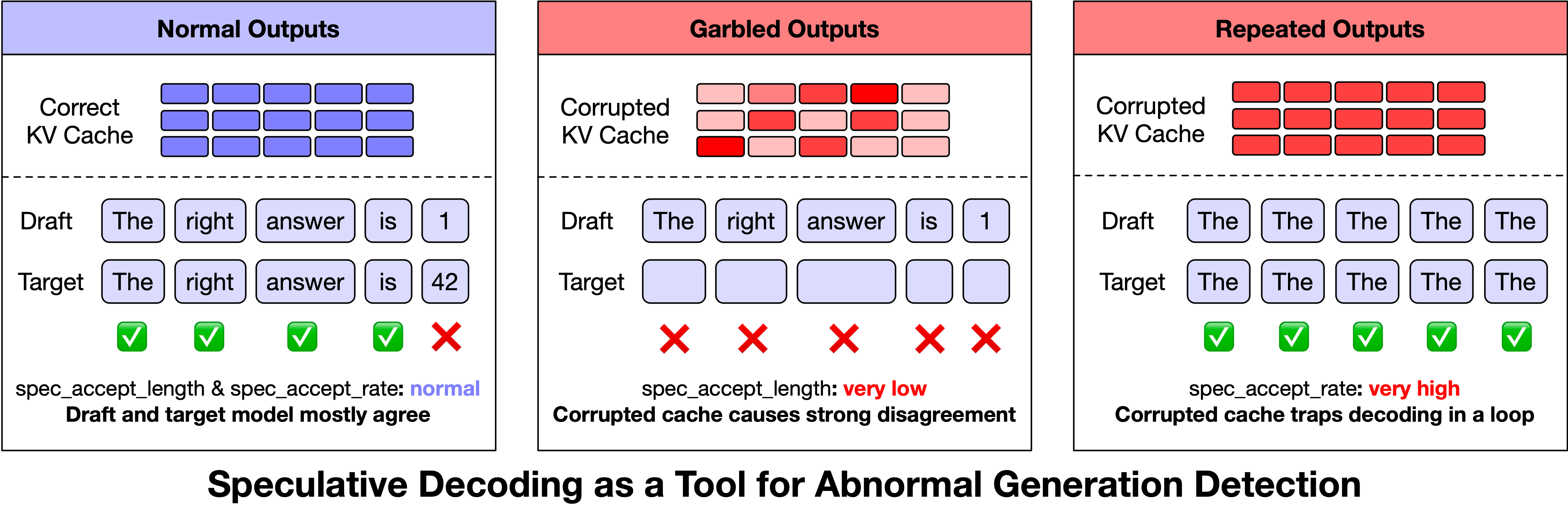 Figure 1: Speculative decoding metrics can serve as important signals for anomaly detection. After repeatedly analyzing inference logs, we discovered an unexpected signal: metrics from Speculative Decoding could serve as useful indicators for anomaly detection. Speculative decoding is originally a performance optimization technique. A draft model first proposes candidate tokens, and the target model then verifies and decides which tokens to accept, accelerating decoding without changing the final output distribution. As shown in Figure 1, we observed that two speculative decoding metrics exhibited stable patterns when anomalies occurred: * **Garbled outputs and rare-character generation** were typically accompanied by extremely low `spec_accept_length`, meaning that the candidate tokens proposed by the draft model were almost entirely rejected by the target model. This suggests a significant mismatch between the KV Cache state of the target model and the draft model. * **Repetition** was typically accompanied by extremely high `spec_accept_rate`, suggesting that a corrupted KV Cache may cause the attention pattern to degenerate, pushing generation into a high-confidence repetitive loop. Based on these observations, we implemented an online anomaly-monitoring strategy. When `spec_accept_length` remained below 1.4 after the generated sequence exceeded 128 tokens, or when `spec_accept_rate` exceeded 0.96, the system proactively terminated the current generation and handed the request back to the load balancer for retry. This strategy extended speculative decoding from a pure performance optimization into a real-time signal for output-quality monitoring, and it became a key tool in our subsequent ablation experiments and root-cause analysis. # 2. Bug Fix #1: KV Cache Race under PD Disaggregation After observing a strong correlation between abnormal outputs and concurrent load, we further investigated the root cause. By analyzing the request lifecycle and the execution timeline under the PD disaggregation inference architecture, we attribute the issue to a KV Cache reuse conflict caused by a misalignment between the request lifecycle and the KV Cache transfer timeline. ## 2.1 Root Cause: KV Cache Reuse Race Induced by Asynchronous Abort To bound tail latency, we introduce a timeout-based request termination mechanism in the inference engine: if the Prefill stage does not complete within a predefined time budget, the Decode stage aborts the request and reclaims its allocated KV Cache resources. However, the abort signal is not properly propagated to the Prefill side, and the Decode side lacks sufficient information to determine whether the KV Cache can be safely reclaimed and reused. Consequently, after the Decode side aborts a request and reallocates the corresponding KV Cache space to a new request, previously issued RDMA writes and ongoing Prefill computations continue executing without being synchronously cancelled. 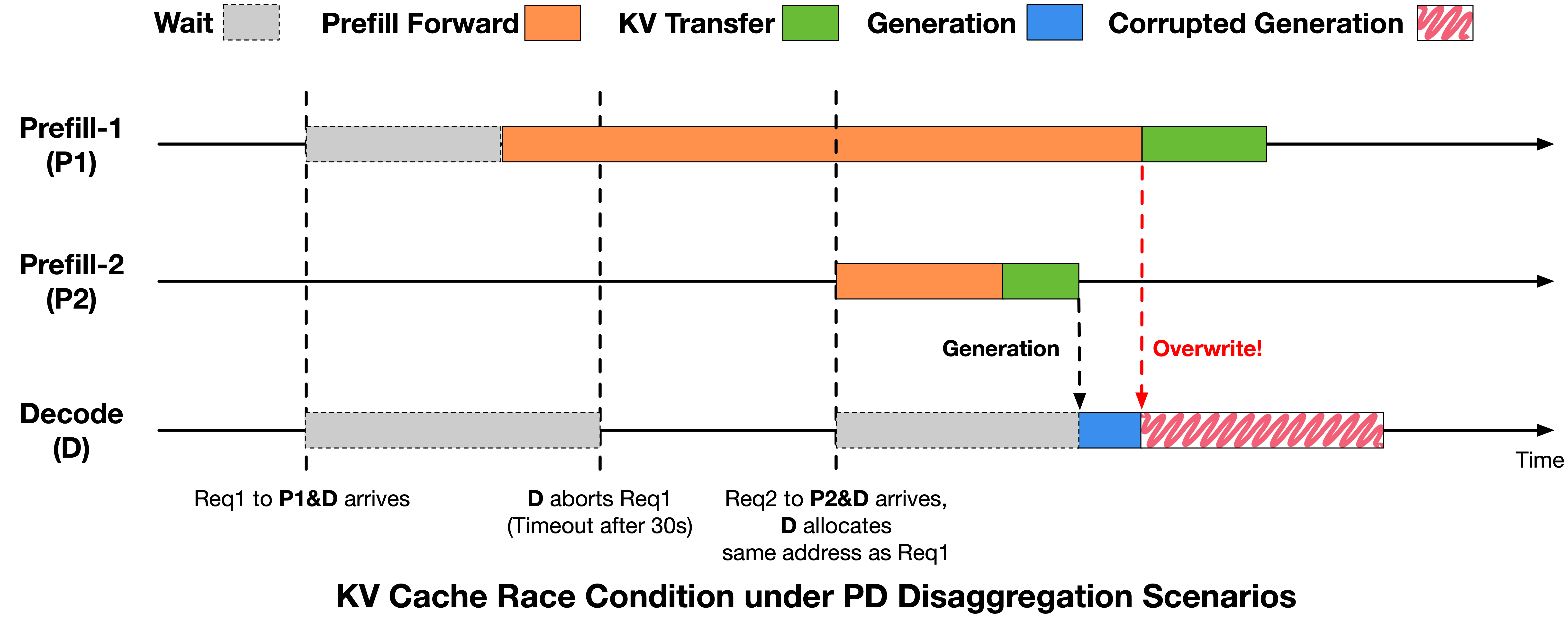 Figure 2: KV Cache Race Condition under PD Disaggregation Figure 2 illustrates the timeline between Prefill and Decode under the PD disaggregation, as well as the resulting KV Cache race condition. Initially, request Req1 is dispatched to Prefill-1 (P1) and Decode (D). Due to queueing delays, Req1 experiences a waiting period at P1 before its Prefill forward begins. Meanwhile, the Decode phase does not receive the corresponding KV Cache data within the expected time window, triggering the timeout mechanism and aborting Req1. Subsequently, Decode reclaims the KV Cache slots allocated to Req1 without correctly notifying P1. Shortly after, a new request Req2 arrives and is assigned to Prefill-2 (P2) and Decode. Due to memory reuse, Req2 is allocated the same KV Cache addresses previously used by Req1. P2 then performs the Prefill forward and initiates KV transfer, completing quickly and allowing Decode to proceed to the generation. Meanwhile, the KV Cache writes issued earlier by P1 for Req1 are still in flight. These writes target the same GPU memory region that has already been reassigned to Req2, overwriting portions of Req2’s KV Cache. As a result, Req2 reads corrupted KV Cache data during decoding, leading to abnormal outputs. ## 2.2 Fix: Enforcing Temporal Consistency for KV Cache Reclamation To eliminate the above race condition, we introduce stricter temporal constraints in the inference engine by establishing explicit synchronization between request termination and KV Cache write completion. Specifically, after issuing an abort, the Decode phase sends a notification to the Prefill phase. The Prefill phase returns a safe-to-reclaim signal only when one of the following conditions holds: (1) no RDMA writes have been initiated, or (2) all previously issued writes have fully completed. The Decode phase reclaims and reuses the corresponding KV Cache slots only after receiving this confirmation. This mechanism ensures that KV Cache writes do not cross memory reuse boundaries, thereby preventing cross-request KV Cache corruption. After applying this fix, the rate of abnormal outputs decreased from approximately 0.1% to below 0.03%. This result demonstrates that, in PD disaggregated architectures, explicit consistency guarantees between cross-node KV Cache transfers and memory reuse are essential to avoid such issues. ## 3. Missing Load-Use Ordering in HiCache Coding Agent workloads significantly increase input length (averaging over 70K tokens) and exhibit high prefix reuse rates. Under such conditions, HiCache (Hierarchical KV Caching) becomes a critical optimization in production systems. However, when KV Cache swap-in overlaps with computation, the current implementation does not guarantee that data is fully loaded before use, leading to potential accesses to unready KV Cache entries. ## 3.1 Root Cause: Read-Before-Ready due to Missing Pipeline Synchronization By analyzing the execution timeline of HiCache, we identify the issue in the cache read path of the DSA-based HiCache implementation. The system asynchronously swaps in historical prefix cache from CPU memory and overlaps this process with computation using separate Load and Forward streams to improve performance. 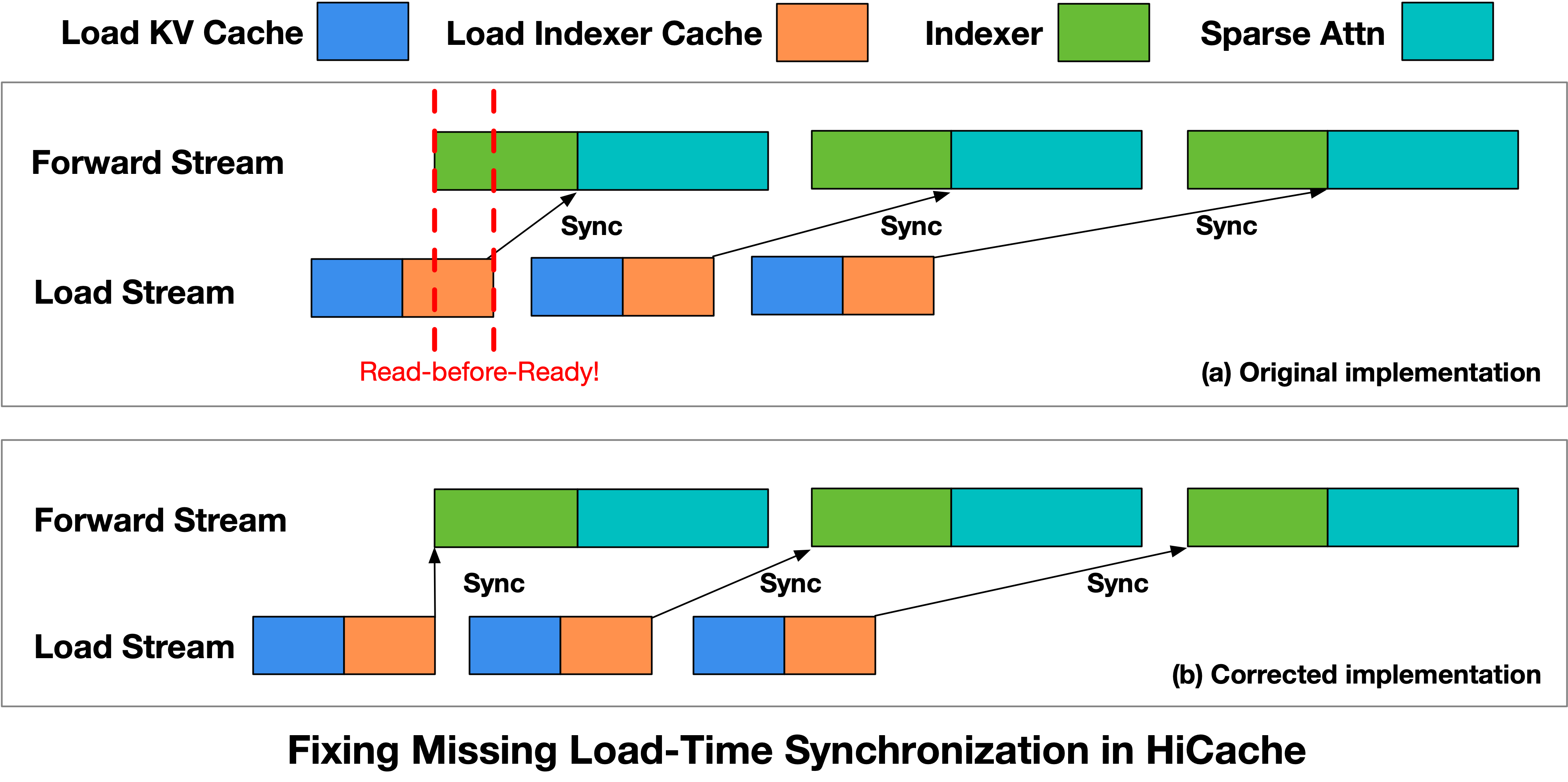 Figure 3: Fixing Missing Load-Time Synchronization in HiCache As illustrated in Figure 3(a), the Load Stream is responsible for loading KV Cache and Indexer cache, while the Forward Stream executes index computation followed by sparse attention. Ideally, the Indexer computation in the Forward Stream should start only after the corresponding Indexer cache has been fully loaded. However, this dependency is not explicitly enforced in the original implementation. Specifically, the Indexer kernel does not establish a synchronization constraint with the completion of the Indexer cache load (highlighted by the red dashed region in the Figure 3). As a result, the Forward Stream may begin execution before the Load Stream finishes data loading, leading to a read-before-ready access pattern, where KV Cache is consumed before it is fully available. This issue causes the indexer computation to operate on incomplete or uninitialized KV Cache, which propagates to subsequent sparse attention computations and ultimately results in abnormal outputs. ## 3.2 Fix: Enforcing Atomicity in the Kernel Pipeline To address this issue, we restructure the HiCache read pipeline (as shown in Figure 3(b)) by introducing explicit synchronization between data loading and computation: * **Explicit synchronization constraint**. A synchronization point with the Load Stream is inserted before the Indexer kernel is launched, ensuring Indexer cache at the corresponding level have been fully loaded. The Forward Stream proceeds with computation only after data readiness is guaranteed, thereby eliminating read-before-ready accesses. After applying this fix, under the same workload conditions, anomalies caused by inconsistent execution ordering are eliminated, and the system becomes stable. This fix has been submitted to the SGLang community as [Pull Request #22811](https://www.google.com/search?q=https://github.com/sgl-project/sglang/pull/22811). # 4. Optimization: Layer-wise KV Cache Split (LayerSplit) The two race conditions above reveal a common system bottleneck: in long-context Coding Agent Serving workloads, the Prefill stage has become the dominant factor in system performance. To control TTFT caused by Prefill queueing, we introduced timeout-based Abort; to alleviate KV Cache capacity pressure on the Prefill side, we introduced HiCache. After fixing these state-consistency issues, we returned to the bottleneck itself: how to improve Prefill throughput while reducing the GPU memory pressure of Prefill-side KV Cache. To this end, we designed and implemented **LayerSplit** , a layer-wise KV Cache storage scheme. Coding Agent workloads typically exhibit long context lengths and high prefix cache hit rates. In this setting, the Prefill phase often becomes the primary performance bottleneck, making Context Parallelism (CP) the dominant parallelization strategy for Prefill nodes in production systems. However, the current open-source implementation of SGLang suffers from redundant KV Cache storage, causing limited KV Cache capacity to become a bottleneck for GPU utilization. 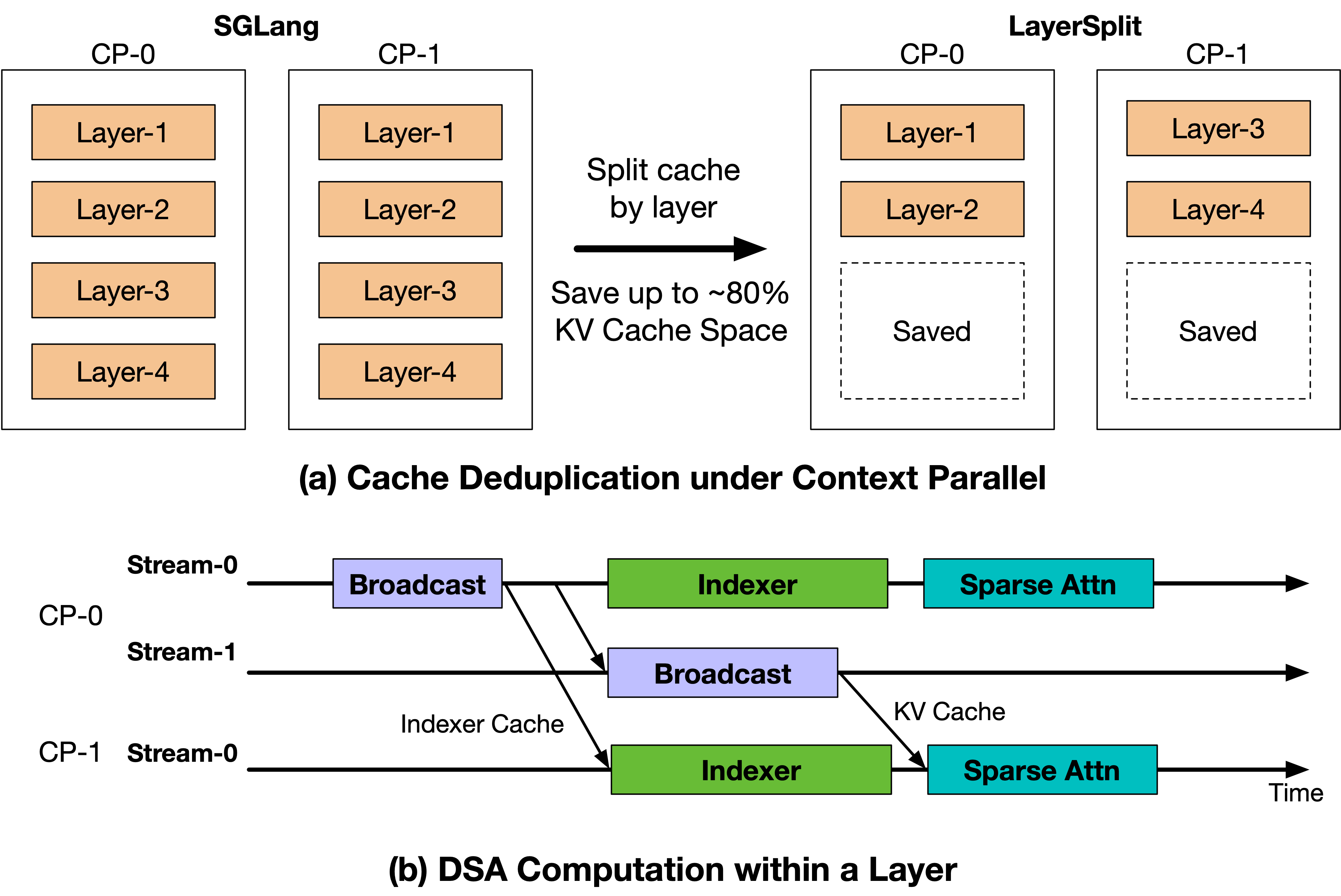 Figure 4: LayerSplit: A Layer-wise KV Cache Storage Scheme To address this issue, we design and implement a layer-wise KV Cache partitioning scheme (LayerSplit). Under this design, each GPU no longer stores the KV Cache for all layers. Instead, it holds only a subset of layers (as shown in Figure 4(a)), significantly reducing per-GPU memory footprint. During execution, different CP ranks collaboratively perform the Prefill computation as illustrated in Figure 4(b). Specifically, the rank that owns the KV Cache of a given layer broadcasts that cache to other participating ranks before the attention computation. To mitigate communication overhead, we further introduce an overlap mechanism between KV Cache broadcast and indexer computation, effectively hiding communication latency behind computation. As a result, the only additional communication overhead comes from broadcasting the indexer cache, whose size is approximately one-eighth of the KV Cache, making the o
Genesis Park 편집팀이 AI를 활용하여 작성한 분석입니다. 원문은 출처 링크를 통해 확인할 수 있습니다.
공유